
- Part 1: What Does a Token Actually Cost?
- Three Ways Agents Keep Token Costs Down
- So What Does Serving a $20 User Actually Cost?
- Model Tiering: The Answer to the Cost Gap
- Part 2: Who Gets to Set the Price?
- The Unlikely Scenario: Monopoly
- The More Likely Scenario: A Contestable Oligopoly
- So, Can You Keep the $20 Plan?
I wrote a second part that adds the perspective of supply constraints. I recommend reading this one first and jump to part 2 afterwards.
I’m a $20 Claude & Cursor subscriber. I only build smaller applications these days, but I’ve been surprised by how much you can do at that price point. Which is exactly why the recent noise around pricing caught my attention.
There was a minor panic when Anthropic seemed to pull Claude Code from the $20 Pro plan, which turned out to be an A/B test. [1] This wasn't the first sign of friction, last year Heise noted the shift towards stricter capping. [2] Dan Nguyen-Huu has a solid overview of how pricing models changed [3] on his Substack.
The opinions I keep reading (mainly on Reddit) fall into three camps:
AI coding is heavily VC-subsidized and unsustainable
Providers need to extract higher margins before IPO (OpenAI & Anthropic)
Coding will become winner-takes-it-all and only affordable to companies with deep pockets.
I think there’s more nuance here. To answer whether $20 and also the more expensive plans are sustainable, you need to work through two questions in sequence:
What does it actually cost to serve a $20 subscriber today?
What kind of market determines whether that price holds tomorrow?
Part 1: What Does a Token Actually Cost?
The common framing “AI companies are all losing money” is technically true but analytically unhelpful. The losses come from R&D: training new models, staying competitive, not falling behind.
Inference is a different story. AI-Companies switched to reporting “gross profit“, the margin on actually running the model instead of total profitability. And here the numbers look quite different. Epoch AI has a good piece on this. [4] In their analysis (figure 1) they estimate the GPT-5 revenue at $6 billion, while having inference cost of $4 billion, a margin around 30%. When you account for operating expenses you roughly land at zero.
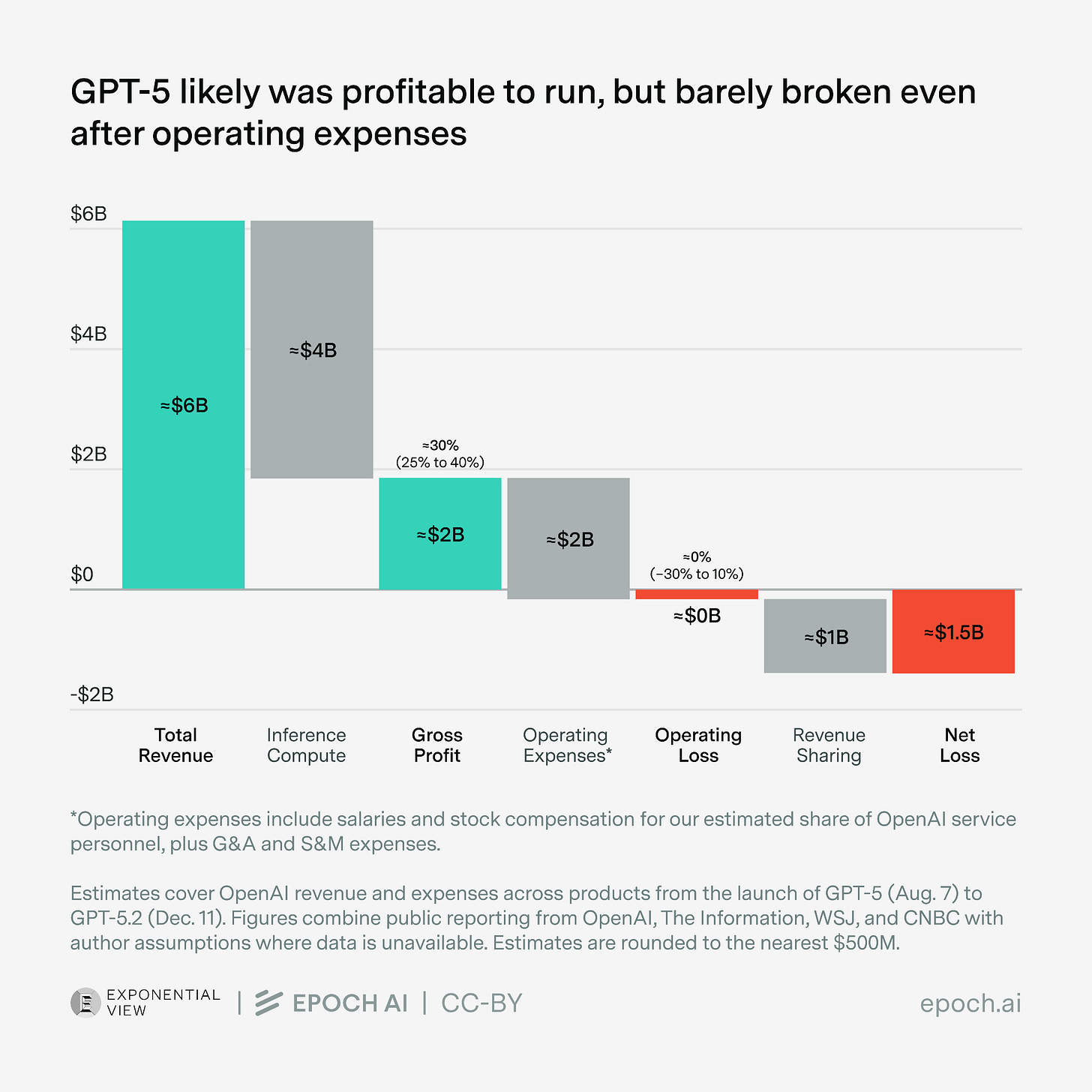
Other data points suggest the same. Dario Amodei (CEO Anthropic) has mentioned gross margins of over 50% [5] on inference on Dwarkesh Podcast. An analysis by The Information puts OpenAI’s compute margins for paying consumer users (not API) at around 68-70%. [6] Martin Alderson’s comparison of Claude pricing vs. open-router equivalents [7] points towards even higher margin.
Why AI companies make huge losses becomes visible in figure 2. They pour lots of money into R&D and train new models, hoping to get a competitive edge. In practice, this edge diminishes quite quickly — a better model is always around the corner. Quitting this race would not be wise either. In game theory, it's called a Chicken Game [8] :every company would benefit if everyone slowed down on R&D spending, but no one can afford to blink first.
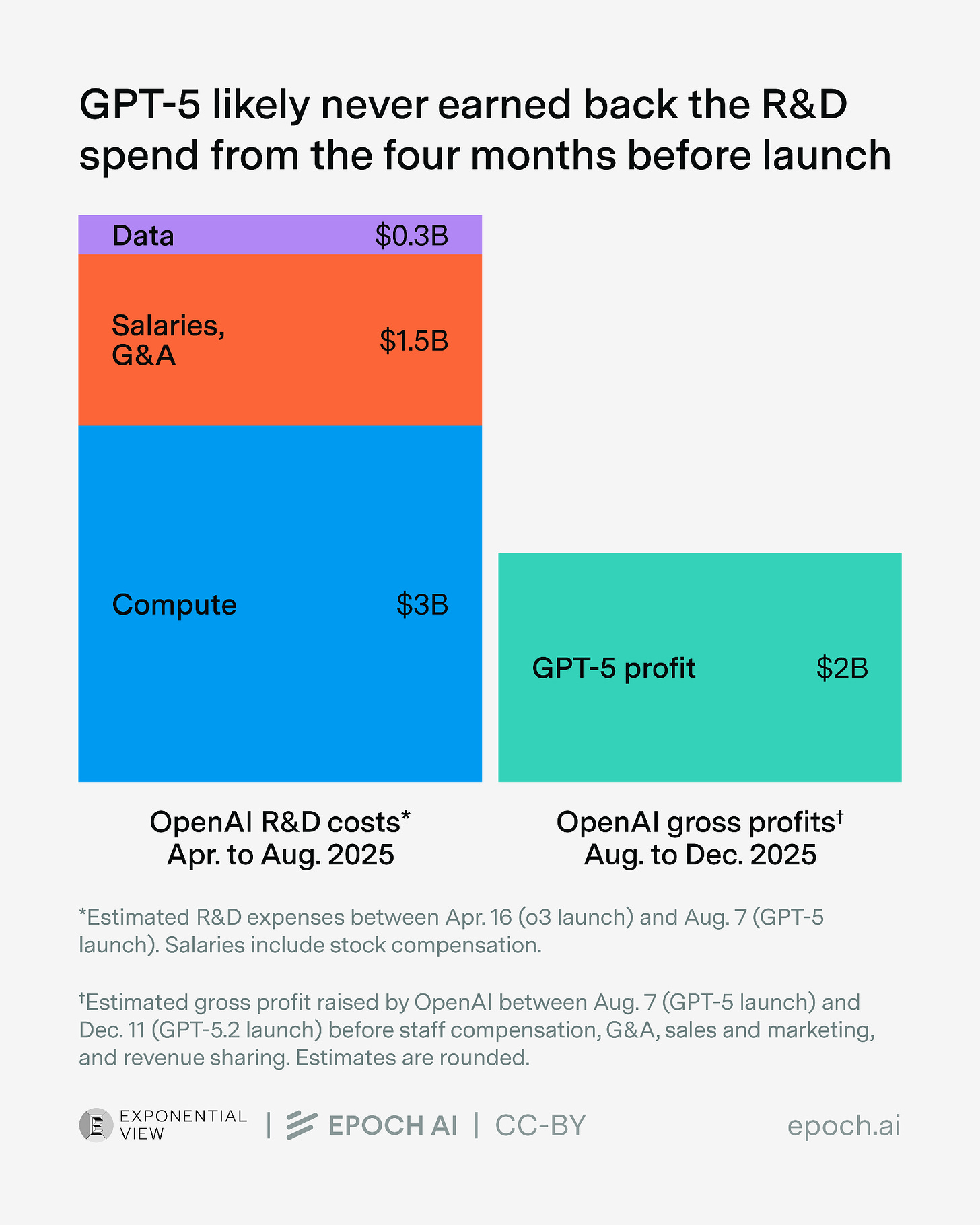
To be honest: I don’t have the real numbers, and these figures come from different companies and different segments. But the directional picture is consistent enough: inference is already reasonably profitable. The token list price isn’t a cost price, there’s margin built in.
That’s the first input into our estimate. But it’s only half the picture. The other half is how many tokens a coding session actually burns.
Three Ways Agents Keep Token Costs Down
The most underappreciated fact about coding agents is that most of their tokens aren’t billed at full price. Here’s why.
Caching. Instead of feeding your entire context to the model on every call, agents pre-compute activations for stable content, like your instructions, tool definitions, markdown files. A good thread here [9] explains the mechanics, and a Reddit thread [10] makes the point that the vast majority of tokens in a typical coding session are cached reads. At Anthropic, cached tokens reads cost significantly less than normal input token price. So when you look at a long context window, most of it isn’t billed at list price, it’s billed at a fraction.
Smart retrieval. Rather than dumping your entire codebase into the context window, agents use search (lexical, semantic, or hybrid) to pull only what’s relevant for each call. Morph’s writeup on agentic search [11] covers how this is evolving. Less context per call means fewer tokens, cheaper sessions.
Model selection. Not every task needs the biggest model. Looking at SWE-bench or SWE-rebench there is high variability in “Cost per Problem Solved”. Routing simpler tasks to cheaper models is increasingly something agents can do automatically.
One more thing worth noting: these tools are not fully optimized yet. Caching strategies, retrieval efficiency, model routing, all of this is still being actively developed. The cost floor hasn’t been reached.
The combined implication: the effective cost of running a coding session is significantly lower than one would expect and it could still improve in the future. Which brings us to the actual estimate.
So What Does Serving a $20 User Actually Cost?
Let me walk through a rough calculation. I want to be upfront: these are assumptions stacked on assumptions, not verified figures. Think of it as order-of-magnitude reasoning.
Claude Code reportedly gives users up to $5,000 in API credits [12] on their $200 plan (I assume this already includes the optimizations above) — a 25x markup at the ceiling
Average usage probably runs closer to $2–3k in practice → effective factor ~10–15x
The $20 plan has 20x lower limits than the Max tier for only 10x less price → effective factor ~5–8x for cheap-tier users
Apply ~50% gross margin on API cost → real-cost factor of roughly 2.5–4x
Utilization on $20 plans skews low, many subscribers use a fraction of their allocation
Working through this, the actual cost of serving a $20 subscriber plausibly lands around $60. Wide error bars. Even if you double it, the story is “subsidized but not catastrophically”.
Model Tiering: The Answer to the Cost Gap
The $60 gap isn’t a secret, and providers aren’t just hoping it closes on its own. Cursor’s new Composer model is a clear signal: rather than serving every task with a frontier model at a loss, they built a purpose-built, cheaper model for everyday coding. Significantly cheaper per token, outperforming Opus 4 on their own benchmarks for a fraction of the cost.
This is model tiering as a deliberate strategy: match capability to task, reduce cost per problem solved, reserve frontier access for where it genuinely matters.
The subsidy is real. But models and coding agents are still improving. So, the package we subsidize today, might be the real value tomorrow.
Part 2: Who Gets to Set the Price?
In Part 1, we saw that the economics of coding agents are more nuanced than “everything is losing money.” According to my napkin math the $20 plan is probably subsidized by roughly 3x against real cost. But whether that subsidy persists, compresses, or disappears depends on something else entirely: what kind of market this becomes.
There are three plausible price points:
$20 — subsidized, current state
~$60 — real token cost, no subsidy
Hundreds or thousands of dollars — value-based pricing, based on developer productivity gains.
Where we land depends on whether this market becomes a monopoly or stays a competitive oligopoly.
The Unlikely Scenario: Monopoly
A monopolist prices up to whatever the customer is willing to pay. If one company owned AI coding, you’d likely be paying closer to what your productivity gains are worth, which for many developers is a lot more than $20.
There are reasons that monopolies could form:
Compute is scarce. Anthropic is already experiencing capacity pressure [13] ,with users outgrowing what Pro and Max plans can comfortably serve. Google is committing up to $40B in infrastructure support. [14] This dynamic structurally advantages hyperscalers (Amazon, Google, Microsoft), which creates concentration risk at the infrastructure layer and one regulators are (hopefully) watching.
AI companies find a durable moat. Someone builds a model so much better than the competition, even in a narrow domain, that users won't switch. There must be something to this: investors are betting billions that one or two players will eventually pull ahead for good. Reality looks different so far though. A model breakthrough buys a few months of differentiation before competitors close the gap. The trajectory looks more like convergence than separation.
The More Likely Scenario: A Contestable Oligopoly
The monopoly scenario has one structural enemy: contestability. A contestable market isn’t one with constant fierce competition. It’s one where competition is possible at any time. That threat alone is enough to keep pricing disciplined. An incumbent who raises prices too aggressively invites a new entrant or loses users to an existing competitor. The mere possibility keeps them honest.
This is different from a monopoly (no credible threat exists) and different from perfect competition (everyone is constantly undercutting each other). In a contestable oligopoly, a few players coexist, margins stay reasonable, and prices don’t drift too far from cost.
There are good reasons to think this describes the current market:
Open source keeps the floor low. DeepSeek, Qwen, Mistral - credible open models mean no closed-source provider can price freely without losing users who switch to self-hosted alternatives. The “good enough” tier is real and improving fast.
Coding agents specifically aren’t a strong moat. The UI and harness around a model, what Cursor, Claude Code, Windsurf, and others provide is replicable. Switching costs are low, most work through IDE even.
There’s already stable pluralism. At the model level: OpenAI, Anthropic, Google and many smaller companies, both for the model and the coding agent layer.
There is also a natural pressure on the cost side. In a contestable market, R&D spending can't spiral indefinitely. If one player pulls back, others eventually follow, because the arms race only makes sense as long as it buys differentiation.
The current price war is happening because it’s a contestable market. Providers are buying users with subsidized pricing because losing the user to a competitor is worse than the subsidy.
So, Can You Keep the $20 Plan?
Most likely yes, for the foreseeable future, but with gradual adjustments rather than a sudden jump.
The scenarios where your $20 plan gets tighter are already playing out: usage limits, model-tiering, slower queues during peak times. But outright removal or a dramatic price hike seems unlikely as long as the market stays contestable. There are too many alternatives, and providers know it.
The real risk scenarios worth watching: a hyperscaler successfully locking up the market vertically, or meaningful regulatory risk around open source. Neither is happening yet, but both are worth tracking.
In the subsidized world, we are paying $20. In a monopoly, you’d already be paying thousands of Euros. In a contestable oligopoly, you stay somewhere in between. My bet is we stay in the oligopoly for a while yet.
Part 2: Supply constraints might explain why and what happens
*AI Disclosure: The research, structuring and notetaking was done by myself, Claude wrote a draft that the I improved iteratively. No links or sources where added by Claude. Image made by Gemini.