The Europe 2031 scenario report [1] got a lot of attention, and the discomfort is the point. It's a fictional narrative, not a policy paper: a five-year story that ends with Washington moving to seize ASML and Europe choosing between becoming an American protectorate, handing the future to China, or sliding into irrelevance. The argument underneath the story is that Europe is too slow, too cautious, and operating at the wrong scale, controlling roughly 5% of global AI compute against the US's 80%, and that the window to change that closes around now.
I had opinions about that. Then I tried to write them down and found most of them were unfounded.
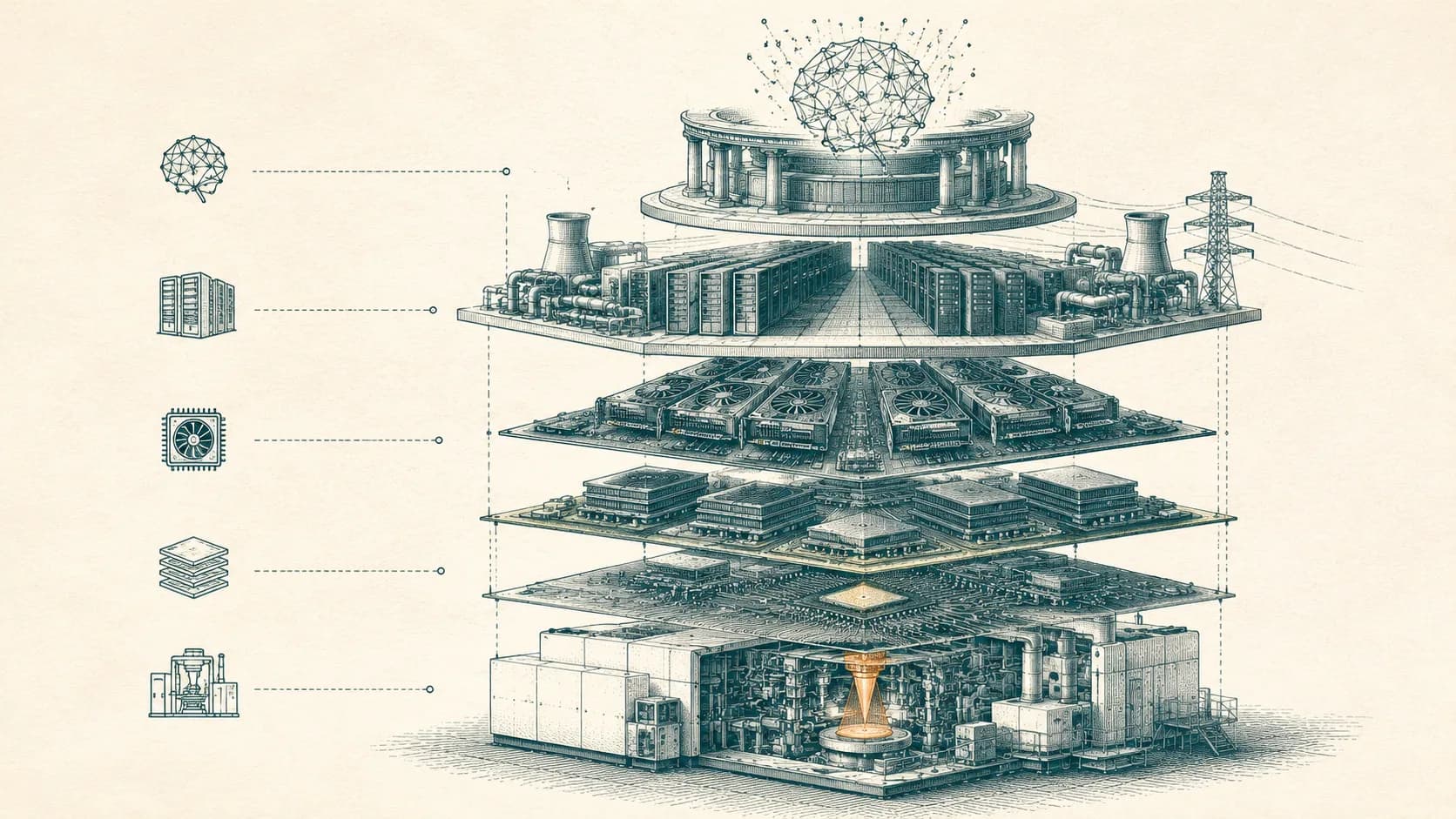
So I did my homework. This is an explainer, not a forecast. I walk down the stack layer by layer and flag two things at each step: where the chokepoints are (one or two companies control everything) and where the complexity is high enough to keep new entrants out.
The cleanest way to read the stack is top-down:
Models — the software that turns compute into tokens
Datacenters — the buildings that turn electricity and chips into compute
GPU production — the pipeline that turns designs into chips
Lithography — the machines that make the chips possible at all
Each layer depends on the one below it.
The Model
A model (more specifically a generative model) consists of an algorithm plus billions of trained parameters. It takes your input and predicts the next token, one at a time, until it has produced a response.
It's worth separating two things the model layer does, because they have very different cost structures.
Training turns data, algorithms, and computation into a finished model. This is the big upfront cost, paid once.
Inference turns that finished model plus more compute into tokens, every time someone sends a prompt. This is the ongoing cost.
When people talk about AI being expensive, they're often blurring these two together, and the distinction matters: one is a sunk investment, the other is marginal cost on every request.
So what do you actually need to build a model? Four inputs, and they don't all behave the same way.
Data is half public and half not. The public half is things like CommonCrawl [2]; the proprietary half is the stuff companies fight over, like Reddit, [3] GitHub [4] or publishers data. [5] There's no mature market for training data yet, legislation is still arguing over whether publicly crawled data is fair game, and there's an open question about whether we're running out of useful human-generated text altogether. [6] [7]
Talent is scarce in the most literal sense. Top-tier researchers are in extreme demand and command salaries in the millions. [8]
Algorithms are mostly public. Transformers, distributed training, data processing, inference optimization, the foundations are out in the open. But the frontier labs have layered a lot of incremental, unpublished improvements on top, and that accumulated know-how is part of what separates them.
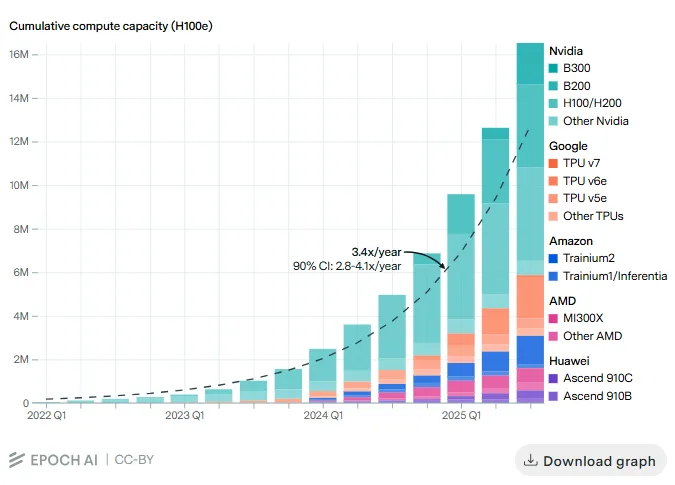
Compute is the input that's becoming the real bottleneck. We're now (2026) entering an era of scarcity, with a genuine race for datacenters and GPUs. More on that as we go down.
The big players are the ones with access to large capital (which buys talent and compute) or to data (which is why a company like Google starts with an edge).
Even as the larger labs have closed off their research, the knowledge keeps leaking into open-source efforts. That diffusion is exactly what keeps margins down, because a capable open model a few months behind the frontier puts a ceiling on what you can charge for the frontier.
Big players: OpenAI, Google (Gemini), Anthropic (Claude), DeepSeek. In Europe, Mistral (mid-tier, multimodal) and Black Forest Labs (Flux, on the image side).
This is the most contestable layer in the stack. There are several serious labs, the algorithms are largely public, and open source is breathing down everyone's neck. I wrote two posts about what scenarios we might end up in the model layer [9][10]
The Datacenter
Go one layer down and you hit something physical. The datacenter is where the AI workloads actually run. It bridges two very different worlds: massive hardware deployments on one side (GPUs, server racks, high-speed optical networking, heavy liquid cooling) and gigawatt-scale electricity on the other. What it produces is compute: continuous, scalable, the raw material the model layer burns through.
The useful unit to look at data centers is power capacity. The largest individual datacenters today run at around 1 gigawatt, and the projected ramp over the next few years is steep. [11]
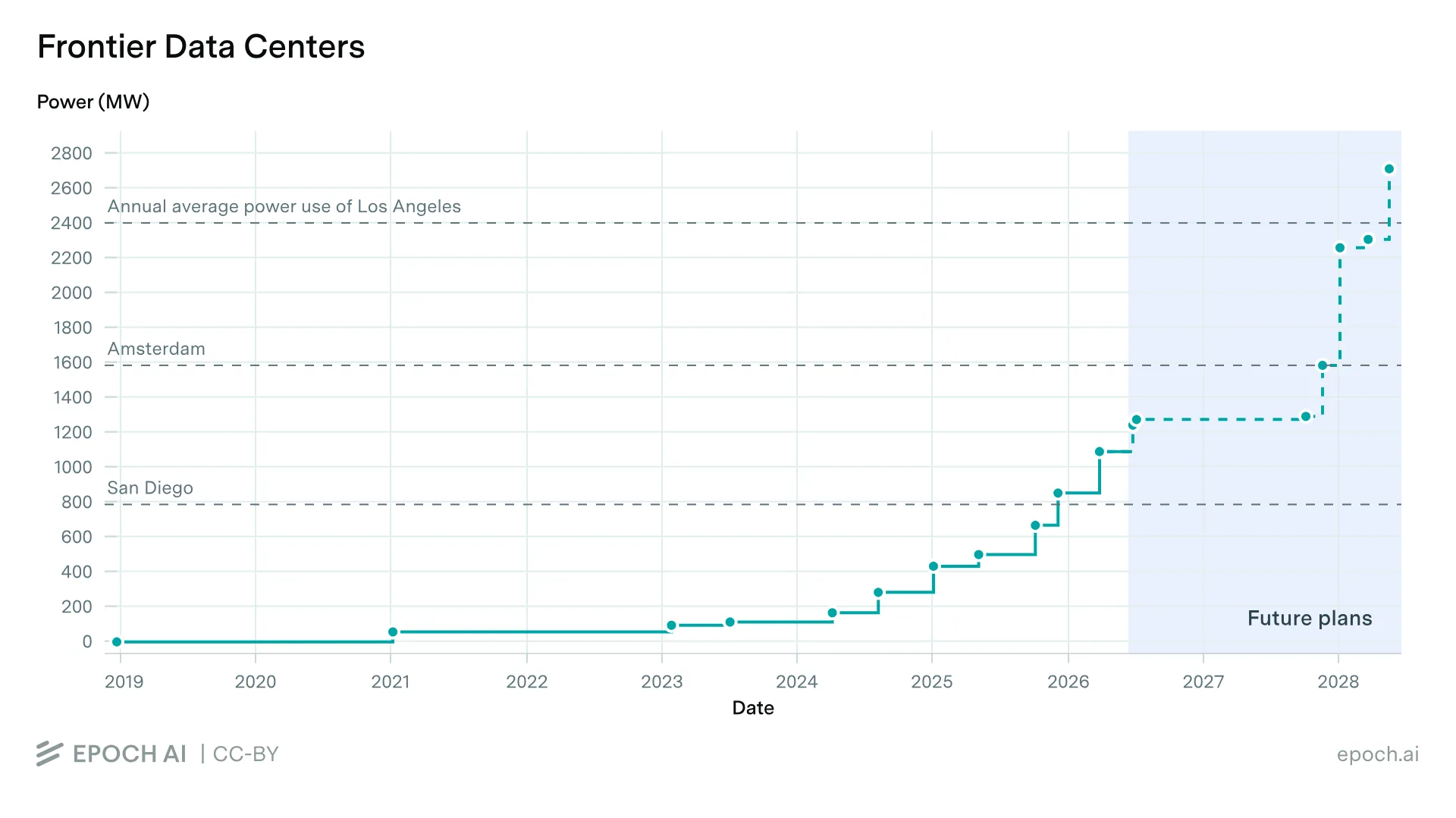
Most of these are owned by the large hyperscalers and platforms: Amazon, Google, Microsoft, Meta. (Who owns the chips inside them is a separate question, and we'll get to it in the GPU section.)
GPU spread
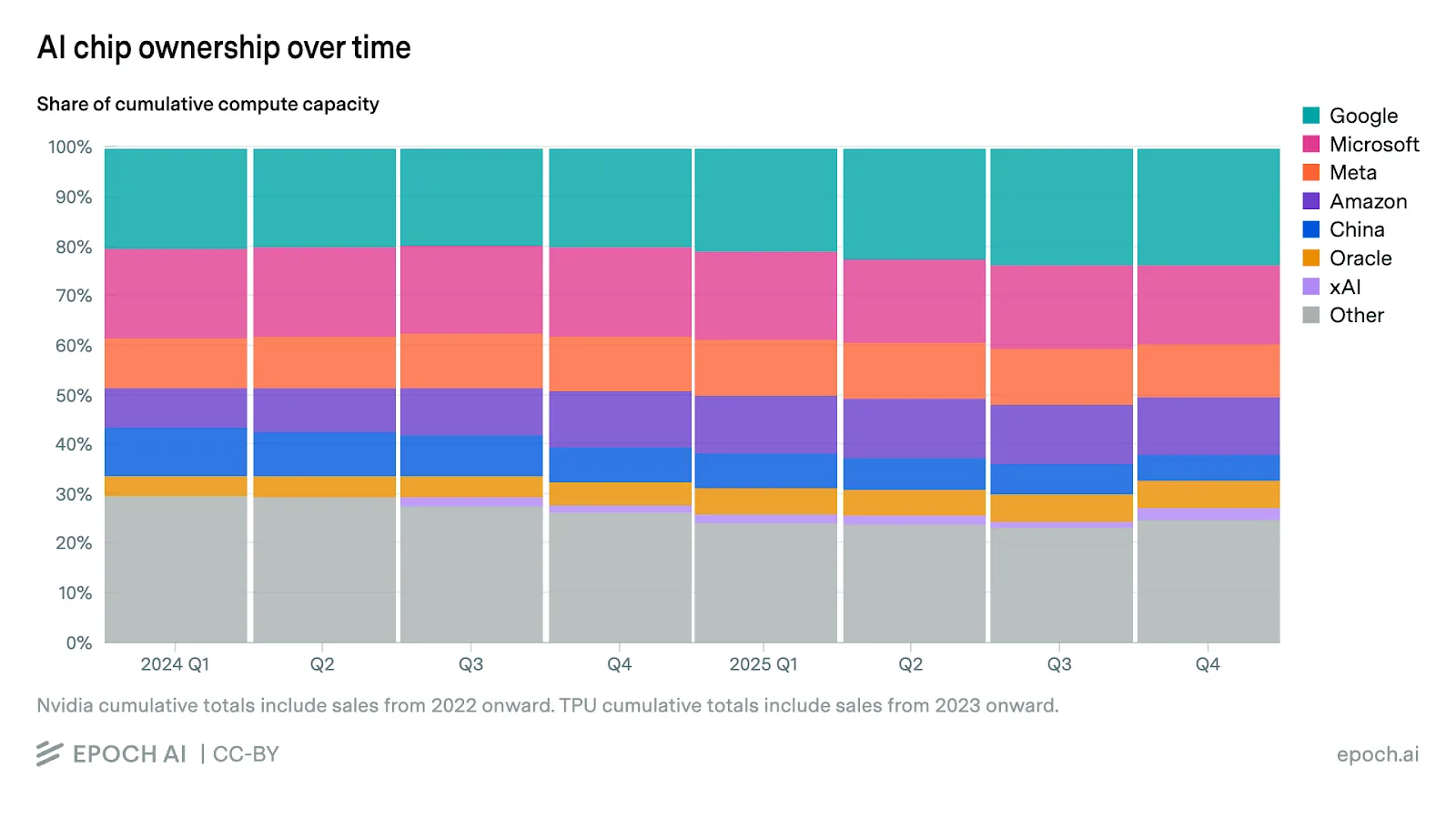
The chart below shows you how Nvidia GPU ownership is spread. Most goes to Google (who also has their own TPUs), Microsoft, Meta and Amazon. China is very restricted on what they can buy from Nvidia and is even now actively banning those purchases to push their own industry. [12]
AI and electricity
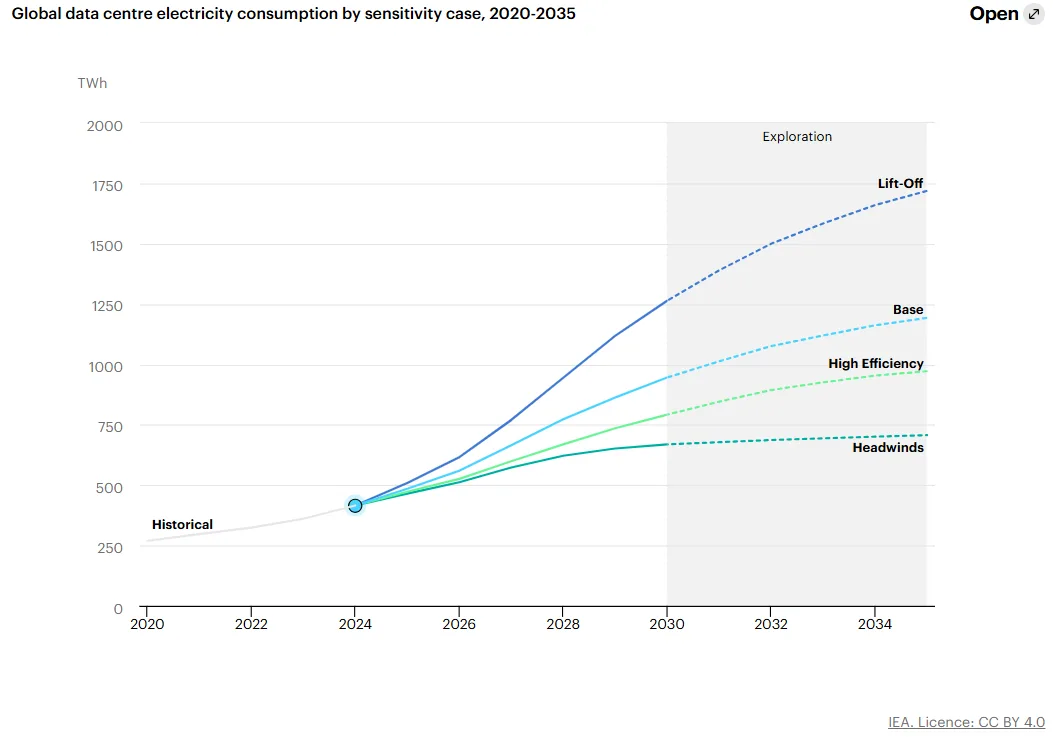
The International Energy Agency estimates that global datacenter electricity consumption was around 415 TWh in 2024, about 1.5% of total global demand, and projects it will more than double to 945 TWh by 2030, just under 3% of global electricity. To put that in context: 945 TWh is roughly two-thirds of the additional electricity that electric vehicles are projected to need globally. [13]
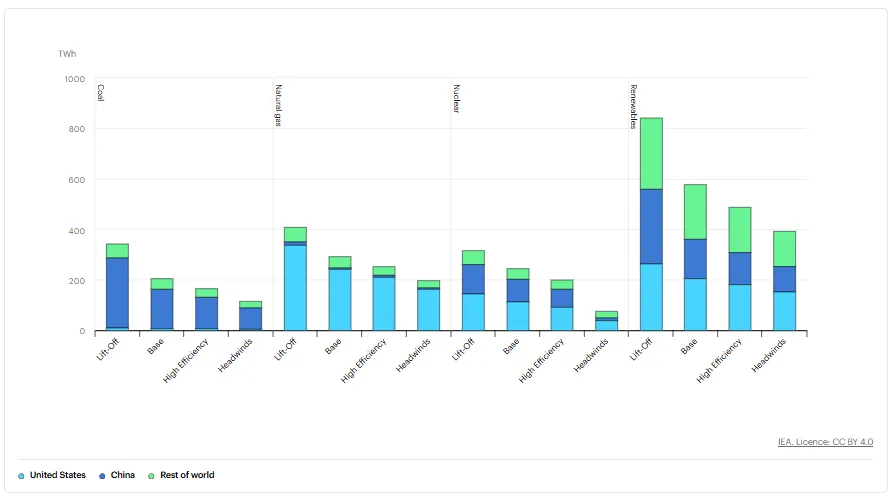
Where this electricity comes from is equally interesting. As the chart below shows, the US, China, and the rest of the world will lean more on renewables, though we may also see China adding coal and the US adding natural gas.
On the other hand, resistance is growing. Data Center Watch report that at least 75 data center projects worth $130 billion were blocked in Q1 2026. [14]
Securing gigawatts of reliable electricity, on a grid that takes years to expand, is becoming the harder constraint. It's not only dependent on industry contracts, but the grid and also the willigness of the people to accept data centers. That's a different kind of moat than the model layer has: it's not about secret knowledge, it's about physical infrastructure and the permits to build it.
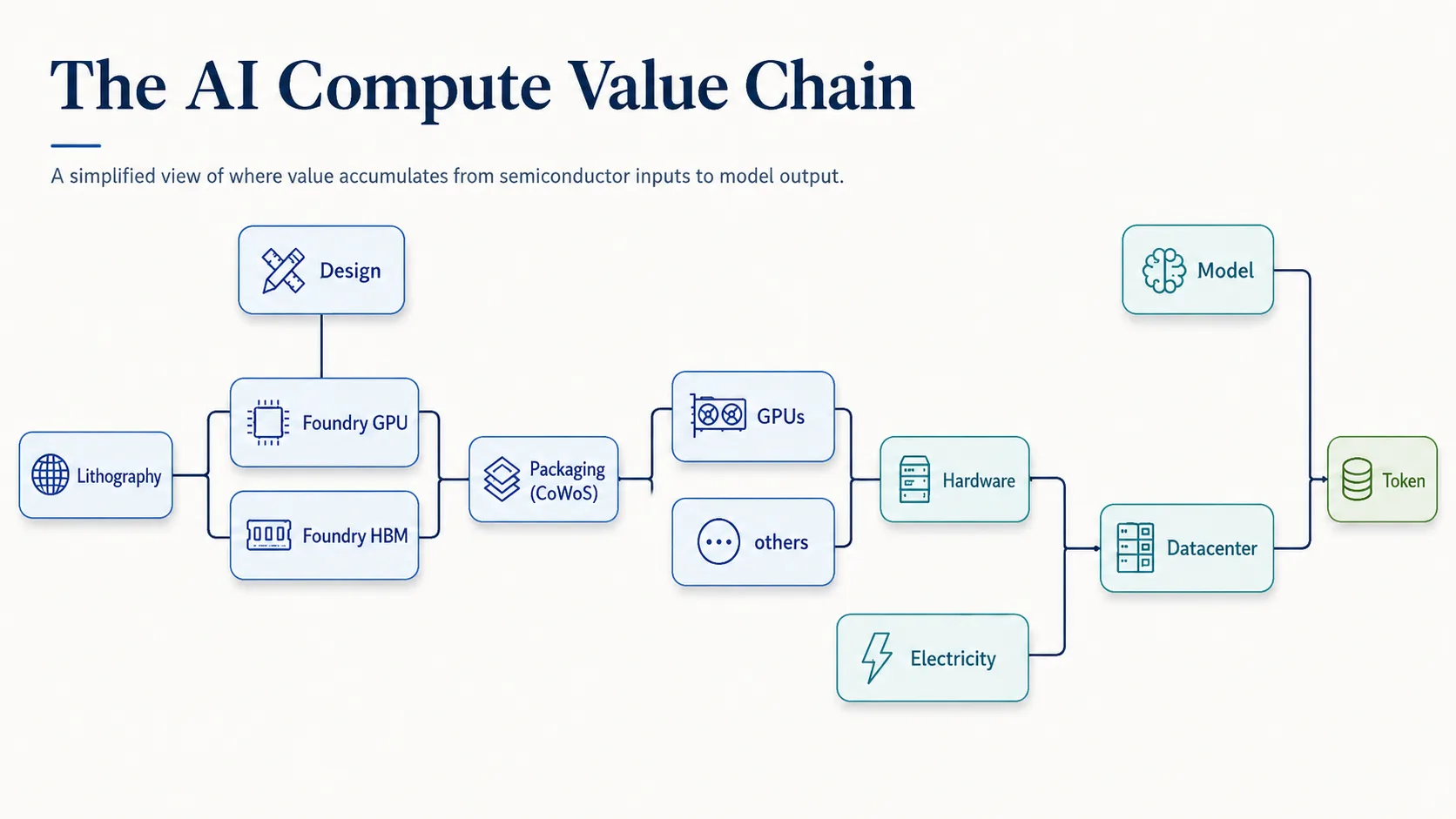
GPU Production
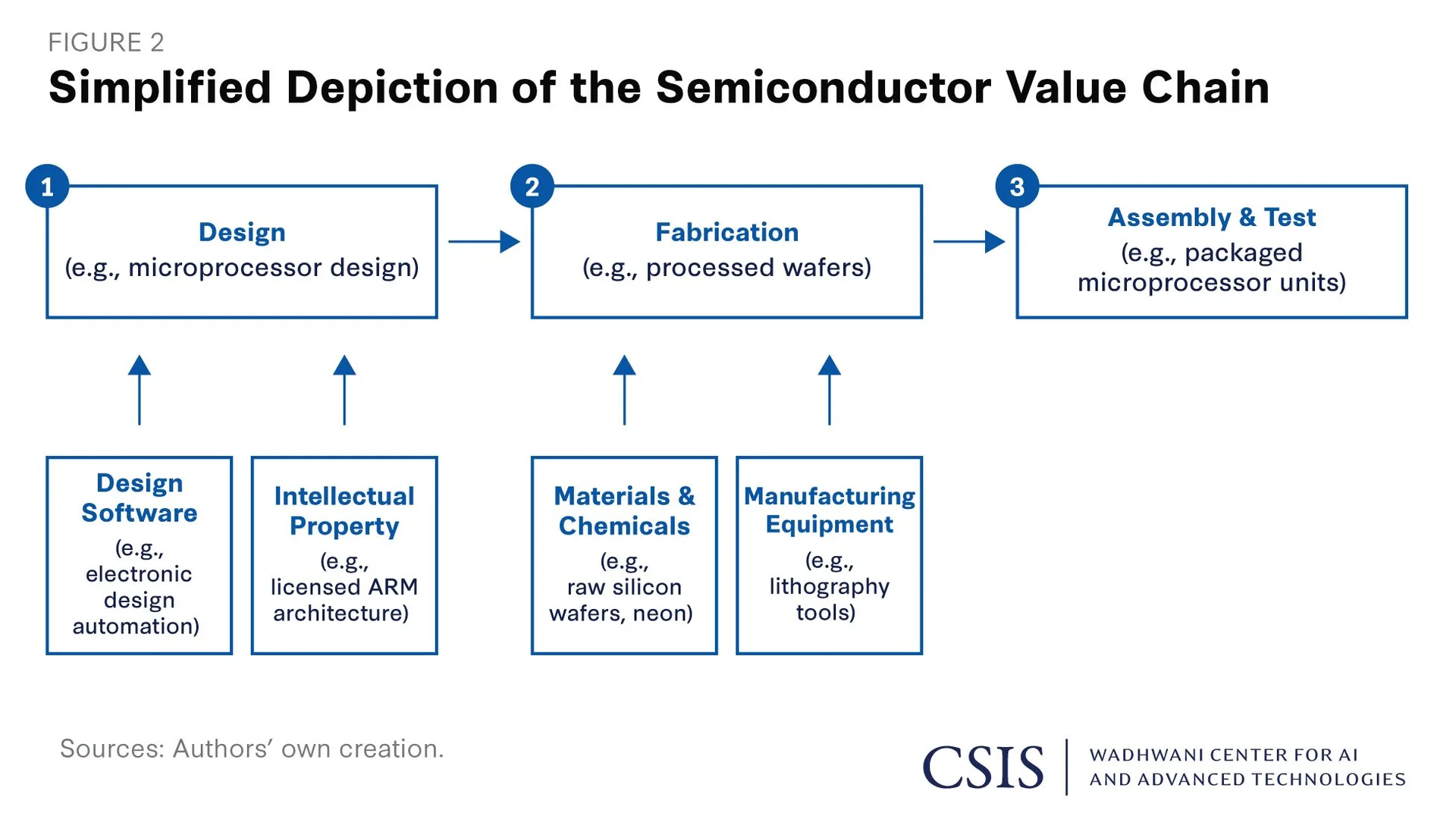
Now it gets genuinely hard. A GPU isn't manufactured in one place or one step. It's a multi-stage pipeline, and each stage is its own specialized industry with its own near-monopoly.
Design
The design is the blueprint: everything the chip can do is decided here, in software, before a single wafer is touched. This is a decades-long engineering discipline that only a handful of companies have mastered, Nvidia chief among them, which is reflected in its market share. Google and Amazon design their own chips too (TPUs and Trainium), as does AMD. [15]
But not all of Nvidia's advantage is in the silicon. A large part of it is CUDA, the software layer Nvidia invested in for years to make its hardware genuinely usable for developers. The ecosystem is the moat as much as the chip is.
Personal note: I've worked with both TPUs and Trainium, and getting anything done outside the CUDA world is an absolute pain.
Foundry (Logic)
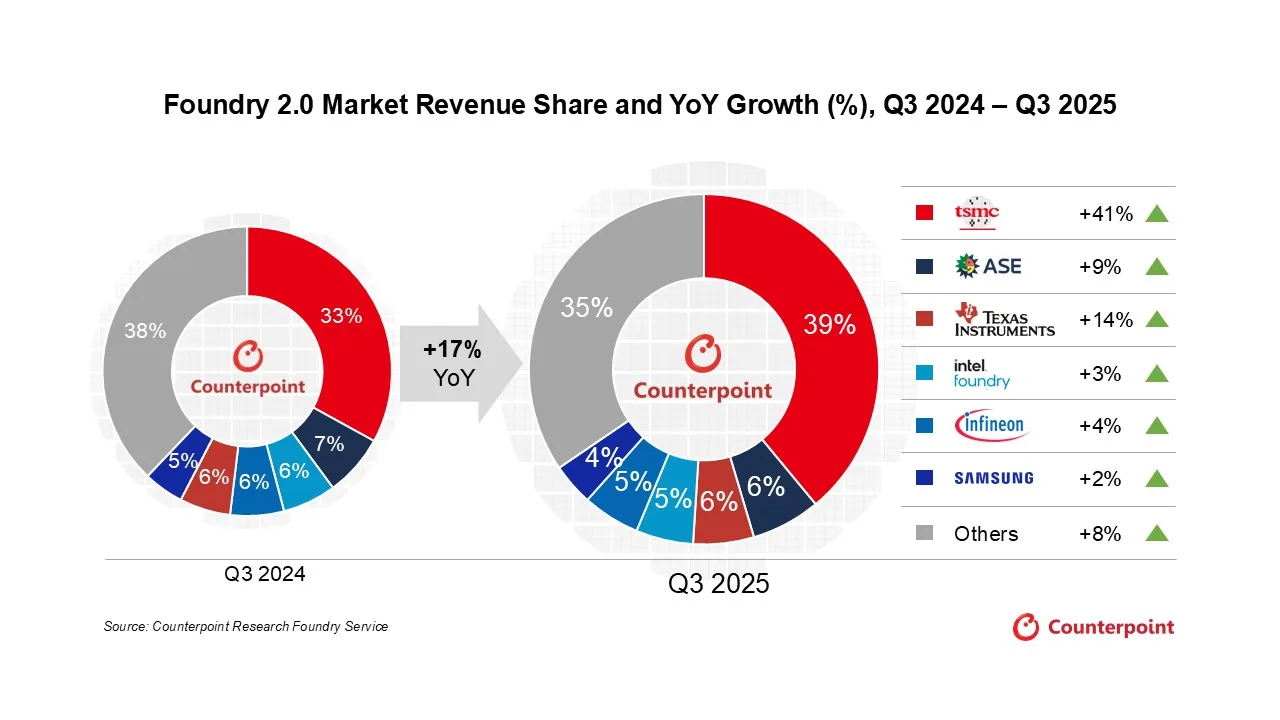
This is where design becomes silicon: the chip is physically manufactured. The stage is sometimes called fabrication, but more often just the foundry.
The engineering problem here is staggering, manufacturing features at the 2–3 nanometer scale. To put that in perspective: a single feature at this scale is roughly 40,000 to 50,000 times smaller than the width of a human hair.
Beyond capital and the lithography machines themselves, the requirements are almost absurd: dust-free, vibration-free clean rooms held to tolerances most industries never approach. The dominant player here is TSMC. [16]
Foundry (HBM)
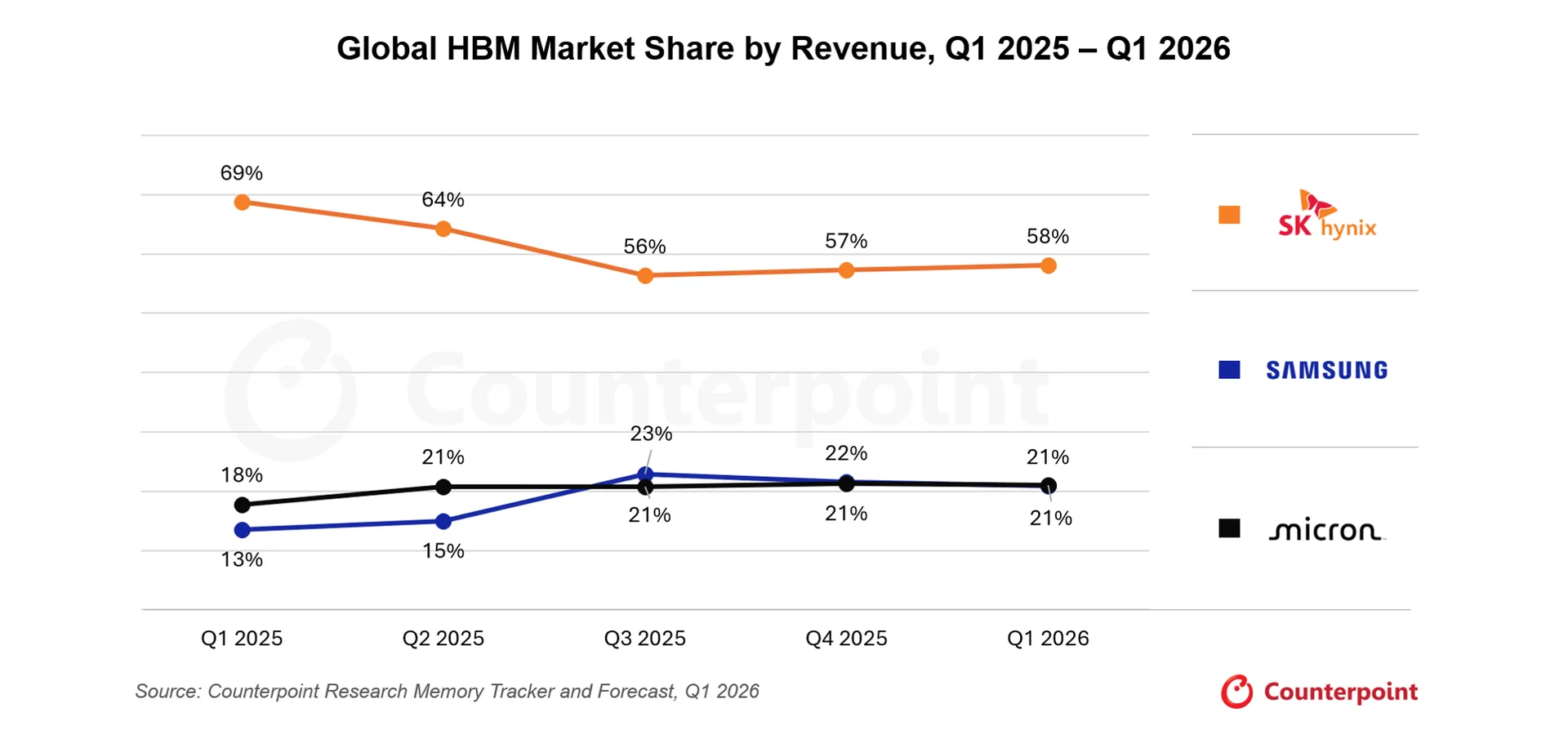
Besides the logic elements a complete GPU needs memory. High-bandwidth memory is fabricated separately. The market is a three-supplier oligopoly: SK Hynix, Samsung, and Micron, with SK Hynix well in front . It matters because HBM is currently supply-constrained, with capacity effectively sold out, so memory, not logic, is often the thing gating how many accelerators actually ship. [17]
Packaging
Finally, the finished logic and memory are fused into one market-ready processor using advanced packaging (CoWoS). As you can guess, that is complicated as well. The dominant player here is, again, TSMC.
The Full Picture
That chart sums it up better than I can in prose. It also maps where each contributor sits geographically, and the takeaway is worth stating plainly: even the United States is heavily dependent on other countries to produce a single chip.
One quick definition, since the chart uses them: EDA (Electronic Design Automation) and IP are the software and pre-built design blocks that let engineers design and simulate a modern chip without starting from a blank page.
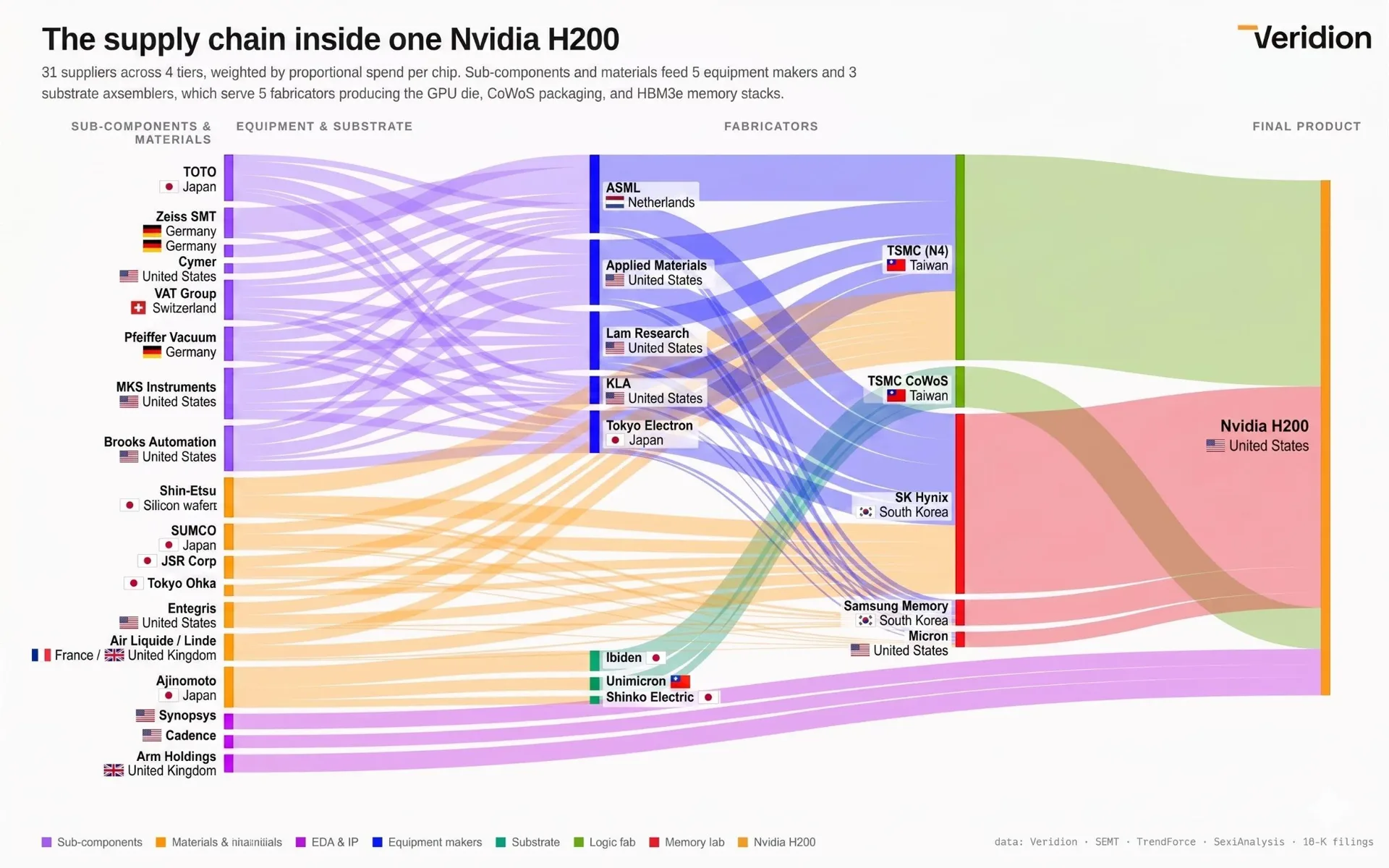
You can see the different elements nicely if you read from right to left - the full GPU needs logic foundry (TSMC (N4), Packaging (TSMC CoWoS), memory (SK Hynix) and EDA & IP. Each supplier itself has quite a few suppliers.
Lithography
Lithography is the printing press of the entire semiconductor industry. Using extreme ultraviolet (EUV) machines, it burns transistor patterns onto blank silicon wafers at scales smaller than anything else humans manufacture. This is the main tool the foundry companies use to build chips.
And there is exactly one company that can do it. ASML is the world's only supplier of EUV lithography machines. Competitors can't replicate the position because of a stack of barriers:
Impossible Technology: EUV requires a chain of near-impossible engineering steps—like blasting molten tin with lasers to create plasma and utilizing atomic-level precise mirrors. These mirrors are made by a single supplier (Carl Zeiss) through decades of exclusive, tightly integrated development with ASML.
Zero Tolerance for Risk: Advanced chip factories (like TSMC) run 24/7 and lose hundreds of millions of dollars if production stops. Because the stakes are so high, chipmakers are entirely unwilling to experiment with an unproved rival machine, regardless of how cheap the sticker price is.
Data Gap: Because chipmakers refuse to buy unproven tools, a new competitor can never accumulate the millions of hours of real-world operating data needed to refine and improve their machines.
Broken Economics: ASML only sells a few dozens of its most advanced machines a year. Because the sales volume is so low and development costs are so high, a new entrant could never sell enough machines to recover their investment.
This is the most extreme chokepoint in the whole chain, and it's worth sitting with how far down it goes. The entire AI boom, every frontier model, every chatbot subscription, every datacenter buildout, ultimately rests on machines that one company in one country knows how to make. [18]
Here is a great video to watch a lithography machine:
What the Market Believes
Here's one way to feel the scale of expectation: of the twenty most valuable companies in the world, fourteen sit somewhere on the AI supply chain I just walked through. Nvidia leads the entire market at over $5T, but the point isn't Nvidia. It's that the AI premium is priced across the whole stack, not just the chip designer at the top. Alphabet, Microsoft, Amazon, and Meta sit at the model and datacenter layers. TSMC, Broadcom, Samsung, SK Hynix, Micron, and AMD are all GPU production. ASML, the lithography monopoly at the very bottom, is in the top twenty on its own. [19]
AI Disclosure: The research, structuring and notetaking was done by myself, Claude wrote a draft that I improved iteratively. No links or sources were added by Claude. Image made by Gemini